
If you've ever worked on a data team, you know the feeling. It's 8 AM, and a Slack message pops up from a business analyst: "The revenue dashboard looks wrong." The rest of your morning is a frantic fire drill, tracing queries and digging through tables to find the root cause. More often than not, the culprit is a silent data failure—an upstream schema change, a batch of malformed records, or a bug in a transformation that went undetected.
These incidents erode the most valuable asset a data team has: trust.
At my organization, we faced this challenge at a massive scale, with over 300 heterogeneous data sources fueling our analytics. The constant fire-fighting was costly and inefficient. We knew we had to move from a reactive model to a proactive one. Our solution was built on two core principles:
No Silent Corruption
Every single bad record must be caught, quarantined, and accounted for. Nothing gets swept under the rug.
"Shift-Left" Quality
We must catch data quality issues during development and deployment, not in production dashboards.
This article shares the blueprint we developed on Google Cloud Platform (GCP) to achieve this, centered around a multi-layered defense model and a powerful concept: the Data Contract.
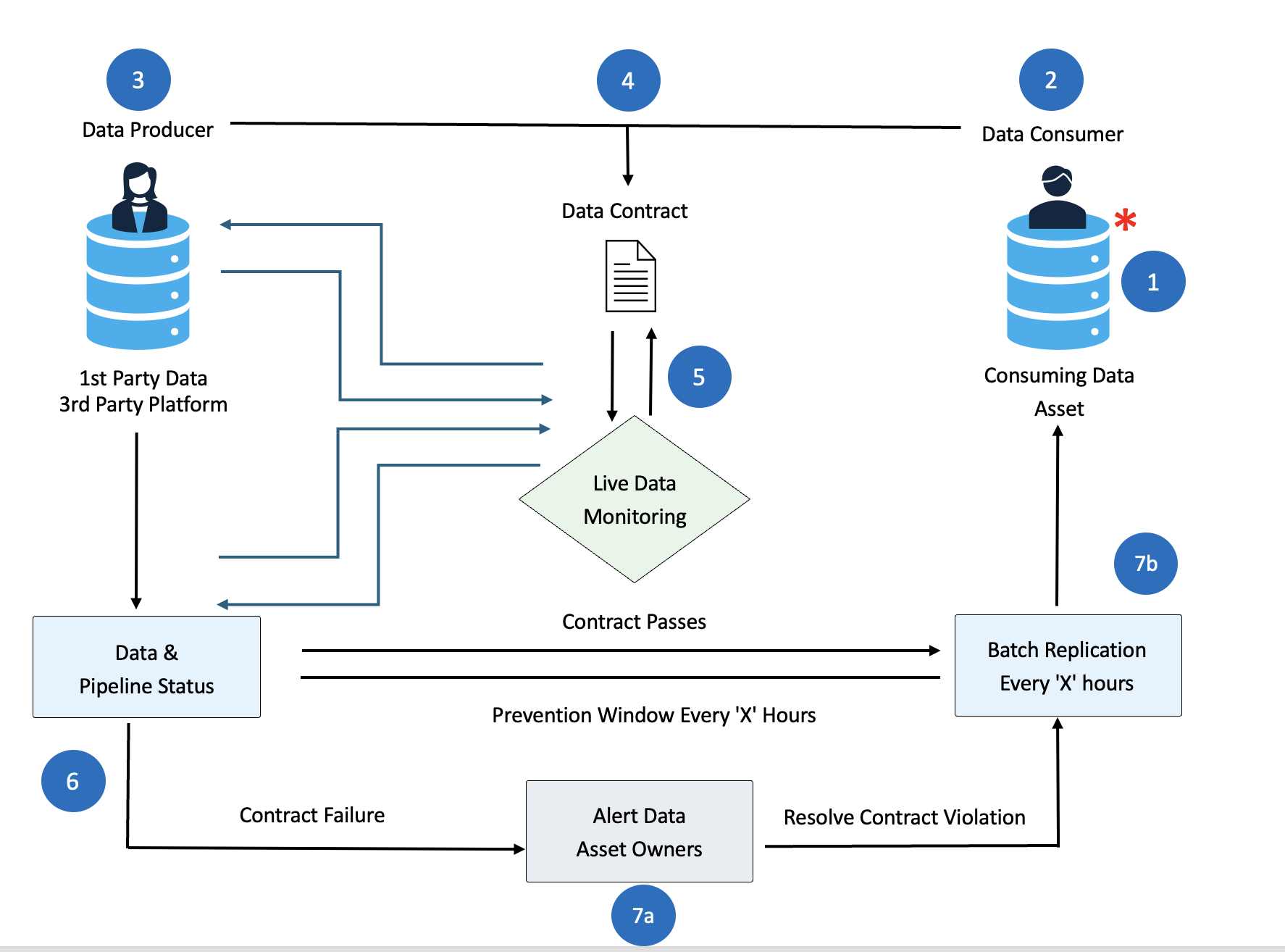
Figure 1: Complete Data Contract Workflow
Legend:
The Framework: A Multi-Layered Defense (L0-L4)
The foundation of our quality assurance strategy is a "defense-in-depth" model. Think of it like a medieval castle's defenses; an invading army (bad data) has to get through multiple, increasingly stringent gates before it can reach the kingdom (your production tables). Each gate is a layer of validation.

Figure 2: Castle Defense Analogy - Each Layer Protects Against Different Data Quality Issues
Defense Layers:
The medieval castle represents your Production Data Kingdom, protected by multiple validation layers that ensure only clean, validated data reaches your analytics tables.
The Perimeter Wall (Ingress Validation)
This is the first line of defense, validating the "envelope" of the data, not its contents. Before we even try to parse a file, we ask:
- • Is the sender authorized? We check IAM permissions or service account credentials to validate the source.
- • Is the package intact? We validate file names, sizes, and checksums to detect truncated or corrupt uploads.
- • Is it in the right format? We check for a valid file naming convention and producer version header as defined in the contract.
Any data that fails these checks is immediately rejected and routed to a quarantine bucket in Google Cloud Storage (GCS) without ever touching our processing engine.
The Gatekeeper (Schema Validation)
Once a file is inside the walls, the gatekeeper checks if its structure is correct. This is the classic schema validation powered by a Pub/Sub Schema Registry.
- • Does it have the required fields?
- • Are the data types correct (e.g., string, integer, timestamp)?
- • Does it violate any basic constraints like nullability or enum sets?
The Royal Advisor (Semantic Validation)
Just because the data has the right shape doesn't mean it makes sense. The royal advisor performs a deeper check on the business logic itself.
- • Are there negative prices or impossible timestamps?
- • Does this product_id actually exist in our dimension table? (Referential integrity)
- • Do the values violate cross-field consistency rules?
The Watchtower (Operational Validation)
The watchtower looks at the overall health of the data flow, not just individual records.
- • Volume: Did we receive the expected number of rows? A 90% drop might signal an upstream issue. We also make this check business-calendar aware, so it doesn't fire a false alarm for an expected drop on a holiday.
- • Freshness: Did the data arrive within its defined SLA?
The Treasury Audit (Downstream Validation)
Finally, after the data has been processed, transformed, and loaded, we perform a final audit. Using tools like dbt tests, we verify the final, aggregated tables.
- • Do the revenue totals in the final table reconcile with the source counts?
- • Are all primary keys still unique after complex joins?
- • Is there any unexpected metric drift compared to yesterday?
If an L4 test fails, we automatically halt the process of publishing data to the final curated tables, preventing a quality issue from ever reaching a production dashboard.
The Single Source of Truth: Data Contracts as Code
This layered defense is powerful, but it only works if all the rules are consistent. A rule defined in Dataflow must match the rule in dbt. To solve this, we made our Data Contract the single source of truth for all validation logic.
A Data Contract is a formal, version-controlled agreement between a data producer and a consumer, defined as a YAML file and stored in Git. It's the blueprint for what "good data" looks like.
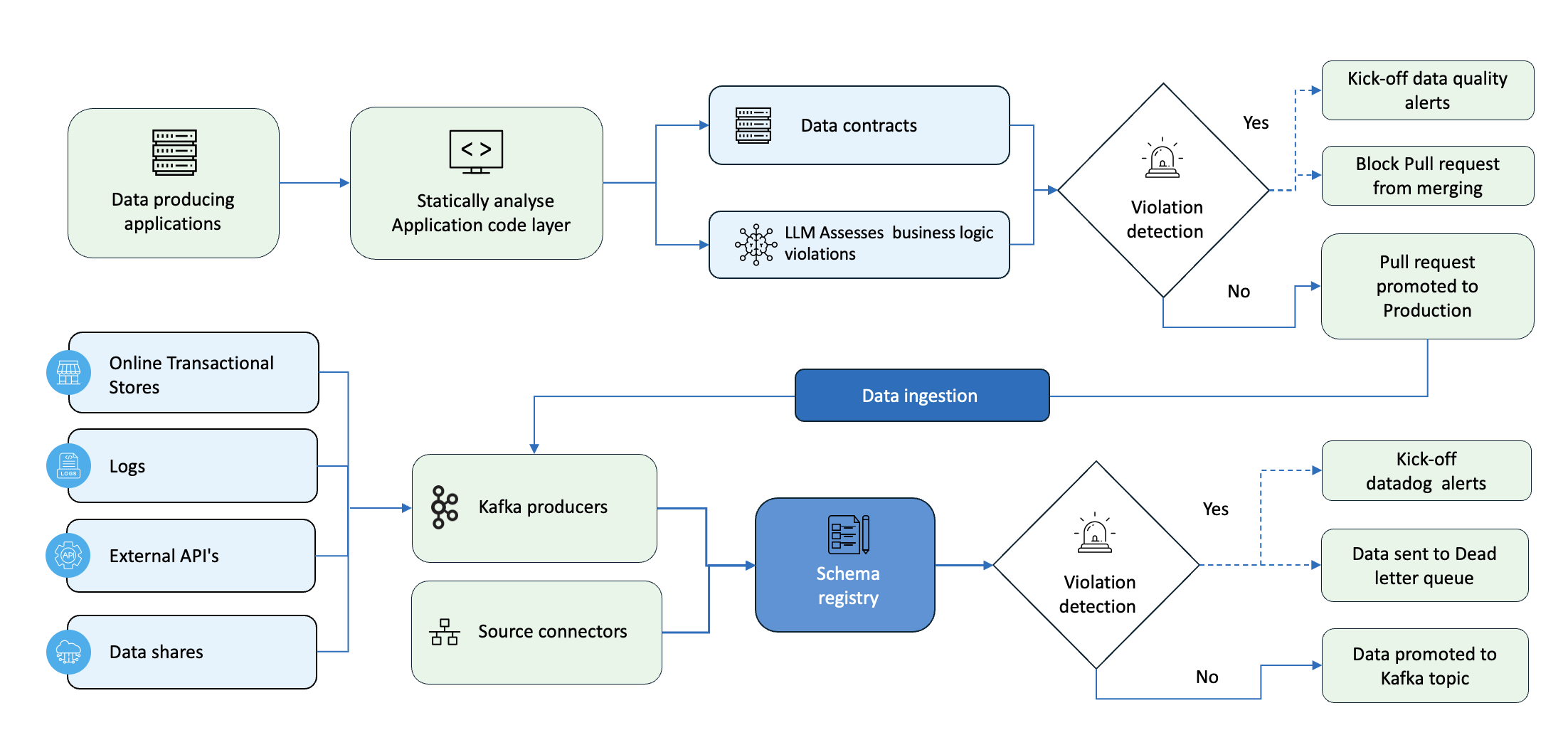
Figure 3: Data Contracts as Code - Dual-Layer Validation System
Dual Validation Layers:
Comprehensive validation at both development time (code-level) and runtime (data ingestion) ensures quality at every stage.
Here's a simplified example:
# data_contract_v1.yml
metadata:
dataset_name: user_events
owner: mobile-app-team@example.com
version: 1
slas:
freshness_seconds: 3600 # Data must be <1 hour old
schema:
- name: event_id
type: STRING
required: true
- name: user_id
type: INT64
required: true
- name: event_type
type: STRING
constraints:
- type: enum
values: ['login', 'purchase', 'logout']
governance:
- name: user_id
pii_classification: CUSTOMER_IDThe magic happens in our CI/CD pipeline. When this YAML file is updated and merged, a GitHub Actions workflow automatically parses it and deploys the rules to all the relevant tools:
- • It generates the Avro schema for the Pub/Sub Schema Registry (L1).
- • It configures the validation logic in our Dataflow templates (L2, L3).
- • It generates the not_null and accepted_values tests for our dbt models (L4).
This prevents configuration drift and ensures every component in our platform is enforcing the exact same rules, all derived from one central, peer-reviewed document.
Putting It All Together: An Automated Remediation Workflow
When a record inevitably fails one of these gates, our automated runbook kicks in, turning a potential fire drill into a predictable, auditable process.
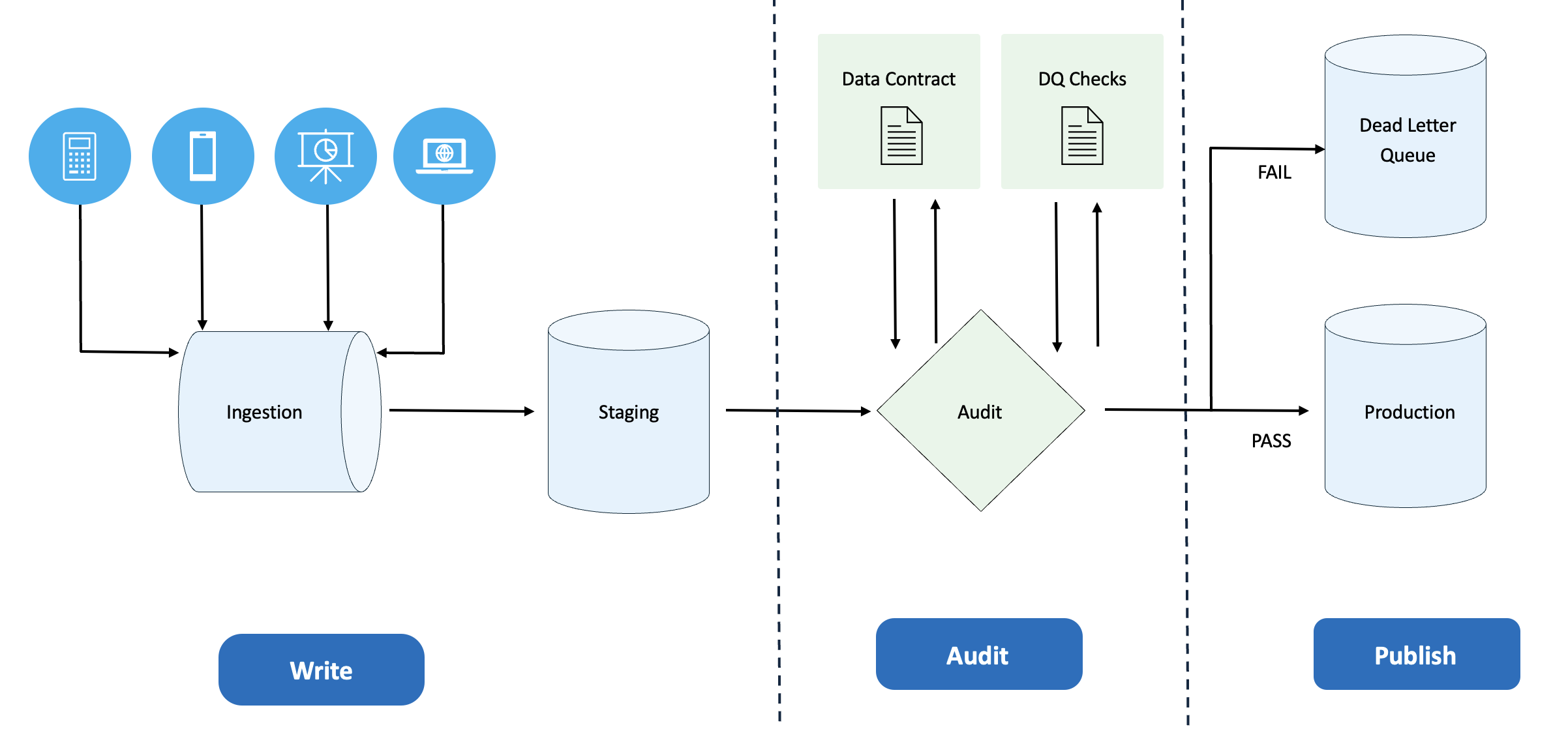
Figure 4: Automated Remediation Workflow - Three-Phase Approach
Workflow Components:
Clear phase separation with dashed lines shows the three distinct stages of data processing and validation.
1. Detect & Contain
A validation failure in Dataflow triggers a side output. The bad record is immediately routed to a dedicated invalid_records table in BigQuery, complete with metadata about why it failed (e.g., "Enum violation in event_type"). The main pipeline continues processing the good data, uninterrupted.
2. Alert & Triage
A structured log is sent to Cloud Monitoring, which automatically creates a Jira ticket and triggers a PagerDuty alert for critical failures. Using metadata tags in Dataplex, the alert is routed to the specific team that owns the source data.
3. Remediate & Replay
The source team receives a detailed report, including the exact contract rule that was violated and sample failed rows. Once they deploy a fix, a Cloud Composer DAG can be triggered to reprocess the corrected data from the invalid_records table, ensuring no data is lost.
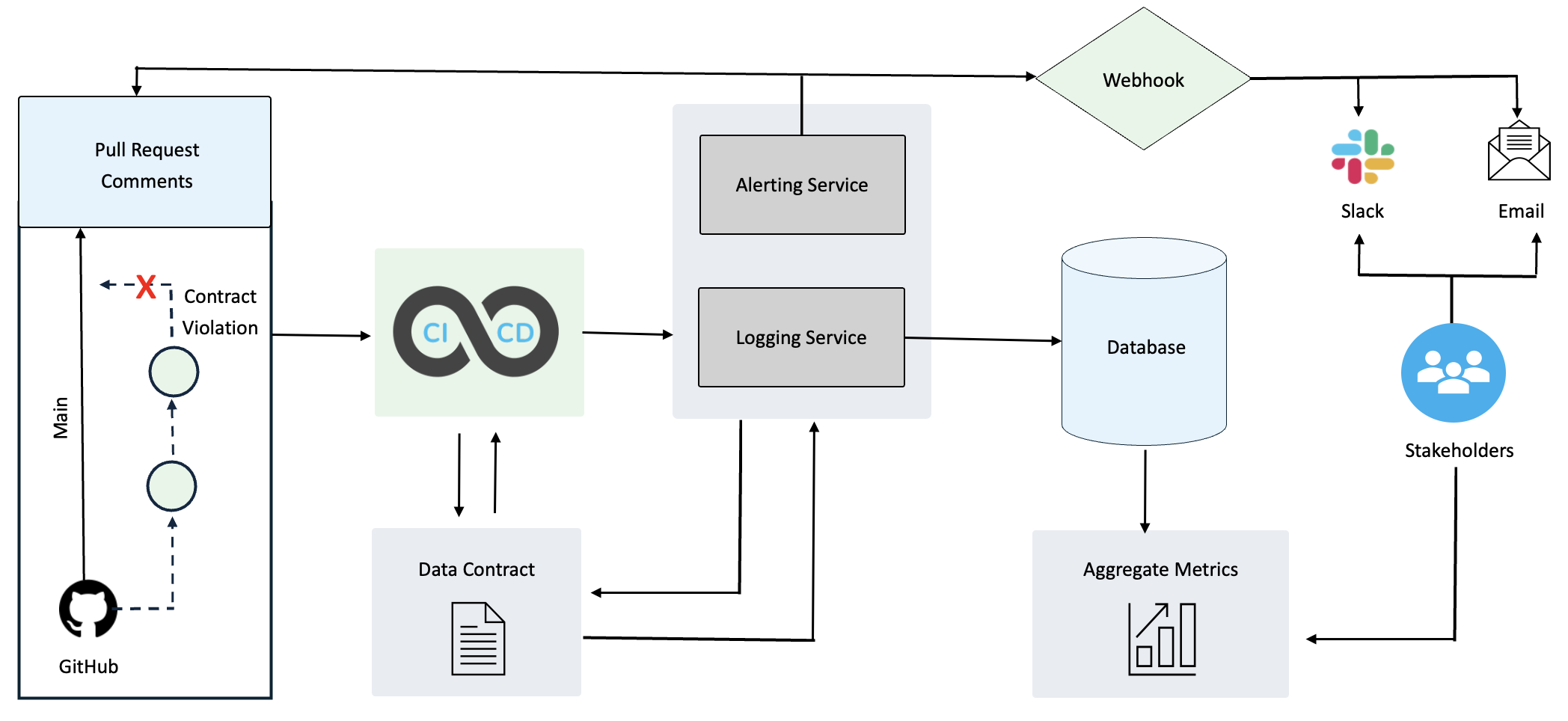
Figure 5: Contract Monitoring & Automated Remediation Flow
Complete Ecosystem Components:
End-to-end workflow from contract violation detection through automated remediation and stakeholder communication.
The Result: A Culture of Data Reliability
By implementing this proactive data quality framework, we've fundamentally changed how our team operates. We spend less time reacting to production incidents and more time delivering value. Our analysts and business stakeholders have renewed trust in the data because they know a robust, automated system is guaranteeing its integrity.
The key takeaways are simple but powerful:
Treat data quality as a first-class engineering problem.
Stop bad data at the door with layered defenses.
Centralize your rules in a version-controlled Data Contract.
Automate everything from detection to remediation.
Building a culture of data reliability doesn't happen by accident. It happens by design.
Found this helpful? Share your thoughts and experiences with data quality frameworks.
References & Further Reading
Data Contracts & Shift-Left Data Management
Learn more about implementing data contracts at the application code level and how to shift data quality management left in your development cycle.
Explore Gable.ai Topics